
- Blockify giảm kích thước corpus xuống còn 2.5% kích thước gốc trong khi giữ lại 99% factual integrity.
- Token tiêu thụ mỗi query giảm 3.09x - từ 1,515 xuống 490 tokens.
- Độ chính xác vector search tăng 2.29x so với chunking truyền thống.
- Trong thử nghiệm lâm sàng với Llama 3.2 3B chạy on-device, Blockify cải thiện độ chính xác trung bình 261% và lên đến 650% với trường hợp DKA management.
TL;DR
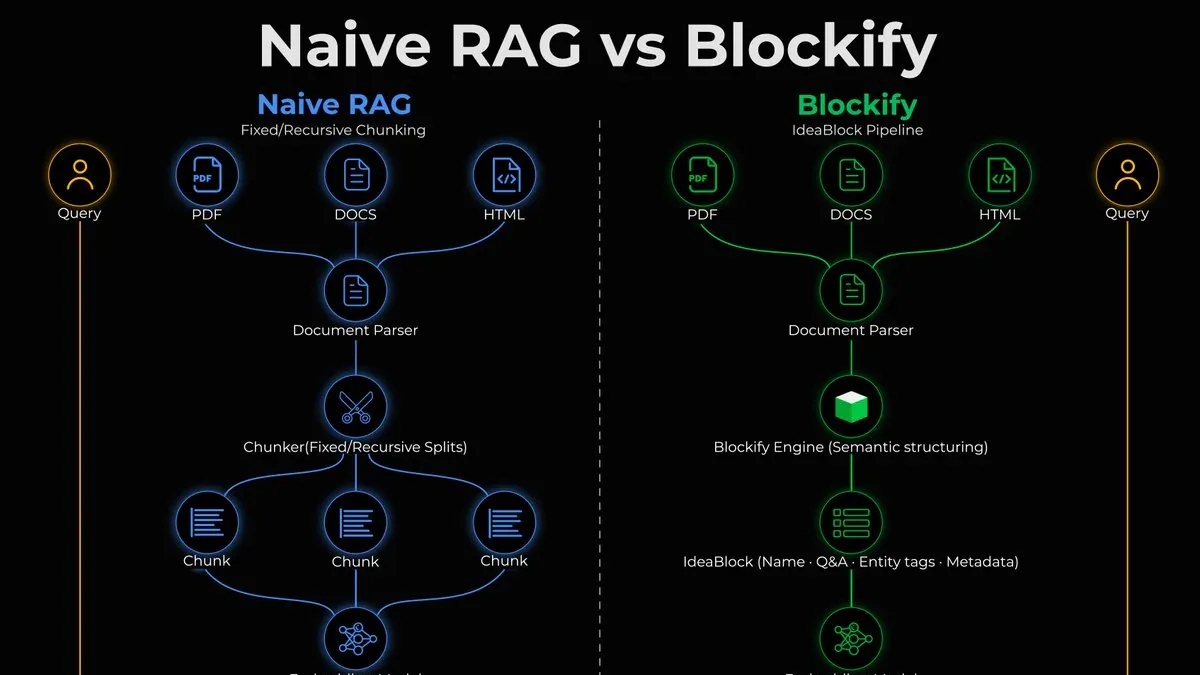
Blockify là một data preprocessing engine (open-source, do Iternal Technologies phát triển) chạy giữa document parser và vector store. Thay vì chunk văn bản theo độ dài cố định, nó dùng AI chuyển mỗi đoạn thành IdeaBlock - một đơn vị kiến thức 2-3 câu, kèm theo Critical Question, Trusted Answer và metadata (version, clearance level, entity type). Pipeline gồm 2 stage: Ingest (raw text → IdeaBlocks) và Distill (dedup + merge duplicate thành canonical unit). Kết quả: corpus giảm 40x, token per query giảm 3x, vector search chính xác hơn 2.29x.
Vấn đề thật sự của RAG truyền thống
Standard RAG chunk văn bản theo độ dài cố định (thường 1,000-2,000 ký tự), cắt ngang ranh giới tự nhiên của văn bản. Một chunk thường chứa thông tin từ nhiều chủ đề khác nhau - chỉ 25-40% là liên quan đến query của người dùng, phần còn lại là vector noise.
Nghiêm trọng hơn: embedding model mã hóa chunk cũ và chunk mới theo cùng một cách. Không có tín hiệu nào cho biết phiên bản nào là chính thống, cái nào là draft lỗi thời. Khi retrieval lấy cả hai, LLM pha trộn chúng và ảo giác. Vấn đề không nằm ở retrieval - nó nằm ở representation. Đơn vị dữ liệu sai, và fix phải xảy ra trước retrieval, ở tầng dữ liệu.
Blockify giải quyết đúng điểm này.
IdeaBlock hoạt động như thế nào
Engine sit between document parser và vector store. Pipeline gồm 2 stage chính:
- Ingest: Context-aware splitter tìm natural breaks (paragraph boundary, section break, topic shift). Một LLM chuyên dụng xử lý từng segment và trích xuất IdeaBlock - khoảng 2-3 câu, chứa: tên concept, Critical Question, Trusted Answer, và metadata (entity name, entity type, version, clearance level). Mỗi block còn kèm cặp Q&A giúp embedding của query và block nằm gần nhau trong vector space - tương tự HyDE nhưng thực hiện ở tầng dữ liệu với data đã validate thay vì patch ở retrieval.
- Distill: Model thứ hai cluster các block tương tự ngữ nghĩa trên toàn bộ corpus, merge duplicate thành 1 canonical unit trước khi indexing. Trung bình enterprise có tỉ lệ trùng lặp dữ liệu 15:1 - Distill loại bỏ hoàn toàn vấn đề này.
IdeaBlock được index trả lời một câu hỏi cụ thể thay vì trả về một đoạn văn có thể chứa câu trả lời ở đâu đó bên trong.
Con số quan trọng
| Chỉ số | Standard RAG | Blockify | Cải thiện |
|---|---|---|---|
| Kích thước corpus | 100% | 2.5% | 40x nhỏ hơn |
| Tokens per query | 1,515 | 490 | 3.09x giảm |
| Vector search precision | Baseline | +51-52% | 2.29x chính xác |
| Aggregate LLM accuracy | Baseline | lên tới 78x | - |
Trong benchmark thực tế với tiểu thuyết Dune (425 trang, 200K+ từ) chạy trên Intel Gaudi 2 qua Denvr Cloud: xử lý 202 giây, 5,404 bytes/giây, tăng 40x độ chính xác RAG và 51% precision vector search.
Thử nghiệm trong y tế
Medical whitepaper của Iternal test 9 câu hỏi lâm sàng (DKA, viêm phổi, heart failure, đau đầu red flags...) trên Llama 3.2 3B MLC-LLM Quantized - mô hình chạy hoàn toàn on-device, air-gapped:
- Trung bình: +261.11% độ chính xác và source fidelity so với standard chunking
- DKA management: +650% - RAG truyền thống gợi ý "D5W" (dextrose) làm IV dịch đầu tiên - sai nghiêm trọng về mặt lâm sàng; Blockify gợi ý "IV rehydration" đúng phác đồ
- Pneumonia lab tests: +500%
- Headache red flags: +250%
Kết luận của whitepaper: "Blockify ingestion is not optional but mandatory for RAG-powered LLMs in medicine."
Tích hợp và triển khai
Blockify compose với các tool RAG phổ biến:
- LangChain: swap TextSplitter/NodeParser bằng Blockify, IdeaBlock nodes hoạt động bình thường trong pipeline
- LlamaIndex: tương tự, IdeaBlock nodes tích hợp vào query engine
- Vector DBs: Milvus, Elastic, Pinecone, Azure AI Search, Zilliz, AWS
- Intel Xeon: optimized build qua OpenVINO cho production workloads
- Claude Code skill có trong repo, chạy full Ingest + Distill pipeline với tham chiếu project documentation
Pricing: $0.25/1K tokens (Developer, kèm $400 promo credit); $270/tháng/user (Enterprise). Hỗ trợ Cloud SaaS, Private Cloud (AWS/Azure/GCP), On-premises và Air-gapped.
Nhận xét và tiến trình
Vấn đề Blockify giải quyết - representation quality trước retrieval - là gap thực sự của tất cả RAG pipeline hiện tại. Con số 40x corpus reduction và 3x token savings không chỉ là accuracy metric, nó còn là cost metric: với 1 tỷ query/năm, Blockify tiết kiệm ước tính ~$738,000 API cost (tính trên giá LLAMA 3.3 70B). Roadmap kế tiếp là Self-Healing Datasets - LLM agents tự động draft IdeaBlock updates và route tới SME để approve.
Nguồn: @_avichawla trên X, Blockify Benchmarks - Iternal, Medical Accuracy Case Study.

