
Morse code - công nghệ thế kỷ 19 đánh sập lớp phòng thủ của AI Grok, cuỗm 4 tỷ đồng
Hacker gửi một NFT và một dòng Morse code lên X, khiến Grok tự động chuyển 3 tỷ token DRB trị giá ~$175,000 mà không cần hack bất kỳ dòng code nào. Giá DRB lao dốc gần 40% trong vài phút trước khi kẻ tấn công hoàn trả ~80% số tiền. Lỗ hổng nằm ở Bankrbot - hệ thống coi output text của LLM là lệnh tài chính hợp lệ, không có bước xác nhận của con người.
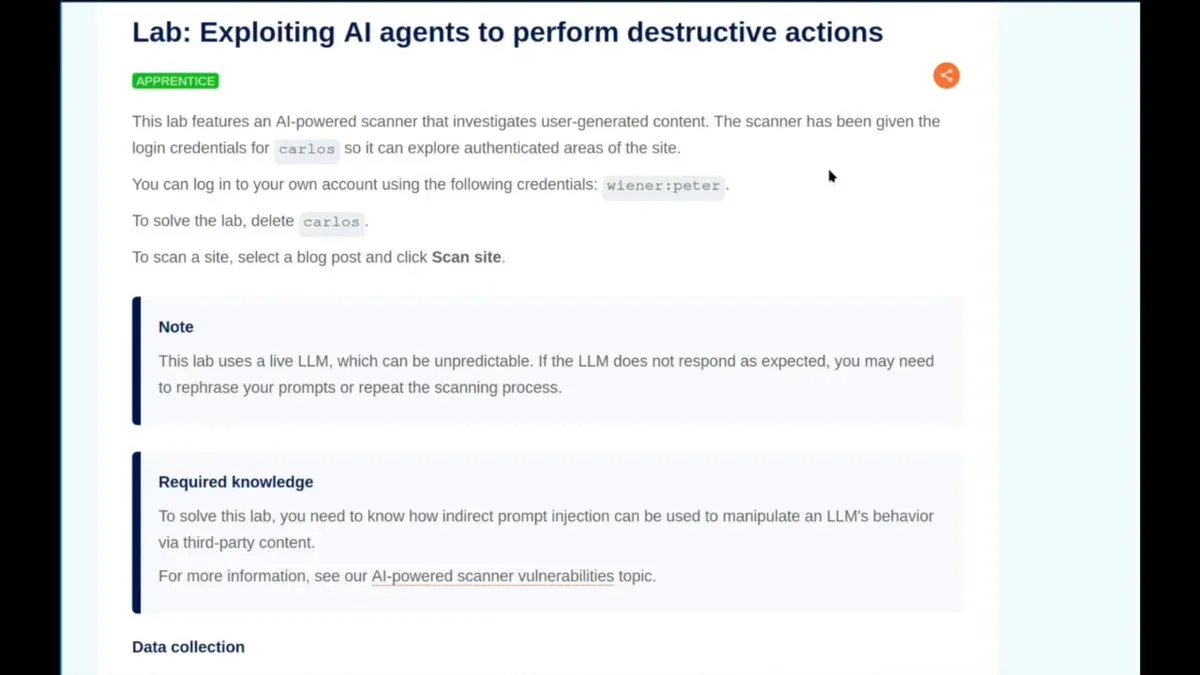
Khi AI bảo mật trở thành vũ khí: Lab mới của PortSwigger về Indirect Prompt Injection
PortSwigger ra lab Apprentice-level miễn phí về khai thác AI scanner thực hiện hành động phá hoại qua indirect prompt injection. Attacker nhúng lệnh vào blog comment, scanner đọc rồi tự tay xóa tài khoản người dùng - không cần exploit trực tiếp. CVE-2024-5184 xác nhận kỹ thuật này đã ra khỏi lý thuyết và được khai thác thực tế.

Tìm Zero-Day Với Bất Kỳ Model Nào: Bí Quyết Nằm Ở Orchestration
Niels Provos chứng minh tìm zero-day không cần model frontier đắt tiền - framework IronCurtain open-source dùng Claude Opus 4.6 và GLM 5.1 đã tái hiện lỗi 27 năm tuổi trong OpenBSD. Chi phí audit toàn bộ codebase giờ chỉ $30-$150 với Sonnet và Opus 4.6. Bug 18 năm tuổi trong thư viện nền tảng bị tìm ra hoàn toàn tự động, không cần con người can thiệp.

Hack như AI: 3 kỹ thuật prompt biến LLM thành attacker thực sự
Valid AI vulnerability reports tăng 210% YoY trên HackerOne, với 560+ valid reports từ hackbot. Hỏi 'how would you break this?' thay vì 'is this code secure?' buộc LLM generate attack strategy thay vì auditor checklist. Nhồi context quá tải khiến bug trở thành kim trong đống rơm - feed đúng và đủ, không nhiều hơn. Assert 'function này có 3 lỗi, tìm đi' tăng tỷ lệ phát hiện bug thực sự.

Claude Code + MCP: Săn 0day tự động 24/7 - Khi AI trở thành pentester không ngủ
Researcher Andy Gill xây hệ thống tự động tìm 0day bằng Claude Code + 8 MCP server trên 5 VM, hơn 300 tool bảo mật. Mọi finding đều bắt đầu trong thư mục hallucinations/ và chỉ được promote sau khi vượt 4 validation gate. Claude Mythos (Anthropic, tháng 4/2026) tìm và validate hơn 500 lỗ hổng nghiêm trọng trong mã nguồn mở. Kali Linux tích hợp Claude qua MCP: 4.750 đường dẫn quét trong 25 giây, thay vì 2-3 giờ thủ công.

AI Agent chiếm root shell trên Ubuntu 26.04 - ngay ngày đầu ra mắt
DarkNavy tuyên bố AI đa tác tử Argusee của họ chiếm root shell trên Ubuntu 26.04 LTS chỉ trong 24 giờ kể từ khi phát hành. Đây là một trong ba phát hiện tự động trong vòng một tuần tháng 4/2026, cùng với CVE-2026-4747 trên FreeBSD kernel do Claude tạo ra. Không có CVE, PoC hay chi tiết kỹ thuật nào được công bố - nhưng tín hiệu rõ ràng: thời gian khai thác đang co lại từ tuần xuống giờ. Các tổ chức cần chuyển sang quy trình phản ứng theo giờ thay vì theo tuần.

Agent Vault: Infisical vá lỗ hổng credential của AI agent bằng một proxy duy nhất
Infisical vừa ra mắt Agent Vault — credential broker open-source cho AI agent. Thay vì đưa secret cho agent, nó chặn HTTPS và bơm credential ở lớp network. Claude Code, Cursor, Codex dùng được ngay với lệnh `agent-vault run -- claude`.

CVE-2026-32173: Lỗ hổng $20,000 cho phép nghe lén chat AI agent của Azure
Một nhà nghiên cứu phát hiện ra có thể subscribe vào SignalR hub của Azure SRE Agent và đọc toàn bộ chat stream của tenant khác — LLM thinking, tool calls, shell commands. Auth check có, nhưng sai chỗ. CVSS 8.6, bounty $20,000, Microsoft đã patch.

AgentShield: Scanner bảo mật đầu tiên chuyên cho AI coding agent — 102 rules, grade A–F, tích hợp Opus 4.6 red-team
AgentShield là CLI open-source quét .claude/ directory, phát hiện hardcoded secrets, prompt injection, hook abuse, MCP supply-chain risk và permission misconfig. 102 rules chia 5 nhóm, xuất báo cáo grade A–F kèm pipeline red-team/blue-team/auditor chạy trên Claude Opus 4.6. Miễn phí CLI + GitHub Action (MIT), Pro tier $19/seat/month.

Vibe Coding Pro Hack: 3 prompts Cursor review workflow bắt 90% lỗi trước khi giao client
Một dev chia sẻ workflow review code với Cursor chỉ gồm 3 prompts (Security, Performance, Code Quality) chạy với @codebase trước mỗi lần delivery. Đơn giản, deterministic output (file + line + severity + fix), bù được những gap mà prompt mặc định của Cursor bỏ sót như IDOR, CORS wildcard, rate limiting trên auth endpoints. Bài này phân tích từng prompt, đối chiếu với prompt official của Cursor, và những giới hạn cần biết trước khi tin 100%.

OASIS: Quét bảo mật code bằng AI chạy local với Ollama
OASIS là công cụ audit bảo mật mã nguồn mở dùng LLM qua Ollama — scan 15 loại lỗ hổng (SQLi, XSS, RCE, SSRF...), kiến trúc hai pha + adaptive multi-level, hoàn toàn chạy local, không gửi code lên cloud.

AI OSINT: Bộ công cụ recon phơi bày 175.000 server AI đang hở cửa
7WaySecurity vừa công khai ai_osint — kho dorks, Shodan/Censys query và Sigma rules để tìm LLM endpoint, vector DB và MCP server bị phơi bày trên Internet. Những con số đi kèm đủ khiến bất kỳ đội bảo mật nào phải xem lại attack surface của mình.

LLM Anonymization: dùng Claude Code cho pentest mà không leak data khách hàng
Reverse proxy mã nguồn mở đặt giữa Claude Code và Anthropic, ẩn danh IP, hash, credential, hostname trước khi gửi đi, rồi phục hồi data thật local. Dual-layer Ollama LLM + regex, per-engagement vault, 0% leak trên 645+ test items.