
- Agentic RAG tốn 3-10x token và 2-5x latency so với one-pass RAG, đẩy latency p95 lên tới 10-15 giây.
- Model performance giảm sau 32.000 tokens dù context window có thể lên đến hàng triệu.
- Tối ưu KV-cache giảm chi phí 10x nhờ tỷ lệ 100:1 input-to-output token.
- Context engineering đang thay thế prompt engineering làm kỹ năng cốt lõi của AI developer.
TL;DR
Getting an LLM to answer questions is becoming the easy part. Thách thức thực sự là làm cho nhiều agents, tools, và workflows hoạt động cùng nhau tin cậy trong production mà không bị hỏng liên tục. Chúng ta đang bước vào giai đoạn mà building the model matters less than building everything around it.
Tại sao đây là thời điểm tốt nhất
chúng ta đang bước vào một giai đoạn mà việc xây dựng mô hình không còn quan trọng bằng việc phát triển mọi thứ xung quanh nó
Nhận định này cộng hưởng mạnh với thực tế năm 2026: các mô hình AI đã đủ mạnh để không còn là điểm nghẽn. Vấn đề nằm ở phần còn lại - hạ tầng, kiến trúc, và toàn bộ lớp vận hành xung quanh. Đây là lúc kỹ năng phát triển phần mềm truyền thống gặp AI, và người biết cả hai đang có lợi thế lớn nhất.
Bản đồ kỹ năng: 9 lĩnh vực cần nắm
Những gì cần học:
RAG - Retrieval-Augmented Generation, nền tảng của mọi hệ thống lấy thông tin từ kho dữ liệu. Stack 2026: hybrid search (BM25 + dense embeddings) + cross-encoder reranker đạt Recall@5 cao hơn 17% so với chỉ dùng hybrid search.
Orchestration - Điều phối nhiều agents, quản lý luồng dữ liệu và xử lý song song. LangGraph là default cho stateful multi-agent control, LlamaIndex Workflows cho retrieval-heavy pipelines.
Evals - Đánh giá chất lượng output ở cả cấp query lẫn cấp trajectory toàn hệ thống. Production targets: Faithfulness ≥0.9, Answer Relevancy ≥0.85, Context Precision ≥0.8.
Memory - Phân tầng bộ nhớ: working memory (ephemeral), conversation summaries (rolling), task artifacts (structured), long-term preferences (stable). Vector DB chỉ là một phần nhỏ.
Routing - Phân loại và điều hướng query đến đúng agent/pipeline. Adaptive RAG với small classifier ở front-end có thể cắt 40% chi phí và 35% latency trên mixed-traffic systems.
Tool Calling - Định nghĩa tool contracts, validate input/output bằng JSON Schema hoặc Zod, xử lý idempotency, bắt buộc có timeout và cost budget mỗi lần gọi.
Validation Loops - Vòng lặp kiểm tra chất lượng output trước khi chuyển sang bước tiếp theo, kết hợp với human-in-the-loop cho các tác vụ không thể hoàn tác.
Fix Loops - Cơ chế phát hiện lỗi, giữ lại context lỗi trong window (không ẩn đi), và tự sửa. Agents nhìn thấy lỗi trước đó sẽ ít lặp lại cùng một sai lầm hơn nhiều.
Context Engineering - Kiến trúc hóa toàn bộ thông tin mà model nhìn thấy: system prompt, retrieved docs, tool results, conversation history - tất cả cùng lúc, không chỉ từng phần riêng lẻ.
Tại sao production ko dễ
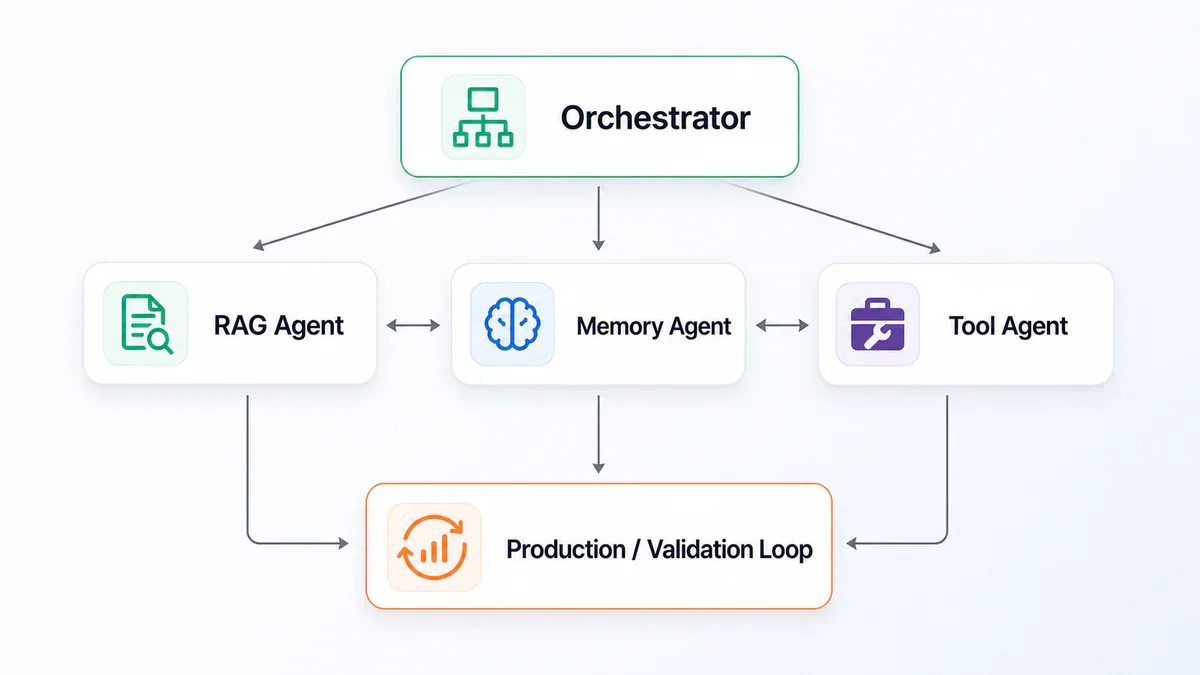
Kiến trúc multi-agent điển hình - mỗi lớp đều là một điểm có thể gặp sự cố
Không có gì cho thấy điều này rõ hơn những con số thực tế:
Chi phí và latency nhân lên: Agentic RAG tốn 3-10x token hơn và thêm 2-5x latency. Một query xử lý trong 1-2 giây với vanilla RAG có thể mất tới 8-12 giây trong agentic loop - đủ để người dùng rời khỏi trang.
Context window không giải quyết được gốc rễ: Dù model providers cung cấp context window triệu token, performance giảm đáng kể sau khoảng 32.000 tokens do "context distraction". Khoảng 40-70% token trong context production thực tế cung cấp giá trị tối thiểu.
KV-cache là đòn bẩy lớn nhất về chi phí: Với tỷ lệ 100:1 input-to-output token, context cost áp đảo API bill. Giữ prompt prefix ổn định để tối ưu KV-cache có thể giảm chi phí 10x. Với Claude: cached tokens = $0.30/triệu, uncached = $3.00/triệu.
"Cost tail" ẩn trong P95: Mean cost thường trông ổn, nhưng một vài query phức tạp chạm iteration cap có thể blow daily budget lên 4x. P99 cost là con số cần theo dõi, không phải P50.
Ngoài ra còn những bẫy kiến trúc khó nhận ra hơn: coordination chaos khi nhiều agent duplicate effort, infinite retry loops khi agent không có giới hạn rõ ràng, tool-call cascades fan-out thành hàng chục traces lồng nhau, và lifecycle drift khi một agent được cập nhật mà cả hệ thống không đồng bộ.
Context Engineering - kỹ năng định nghĩa thời đại
Trong danh sách 9 kỹ năng trên, context engineering có lẽ là điểm mù lớn nhất hiện tại. Một nghiên cứu chạy qua 9.649 thí nghiệm kết luận rằng chất lượng context mà model nhìn thấy quan trọng hơn chất lượng prompt.
Sự khác biệt cốt lõi:
Prompt engineering tối ưu cách bạn hỏi - đủ tốt cho tác vụ đơn, một context window
Context engineering tối ưu toàn bộ những gì model nhìn thấy trong suốt vòng đời agent - cần thiết cho multi-step workflows với hàng chục quyết định liên tiếp
Skills cần thiết để làm tốt context engineering không còn là "viết prompt hay" - mà là software engineering thực sự: thiết kế token budget cho từng zone trong context window, dùng file system như extended memory, chủ động giữ lại error context thay vì ẩn đi, và đặt todo.md để combat "lost-in-the-middle" problem trong long workflows.
Bắt đầu từ đâu
Thị trường không cần thêm chatbot hay wrapper quanh các model. Câu hỏi thú vị năm 2026 là: ai có thể làm cho nhiều agents, tools, và workflows chạy tin cậy trong production, không hỏng sau mỗi vài ngày?
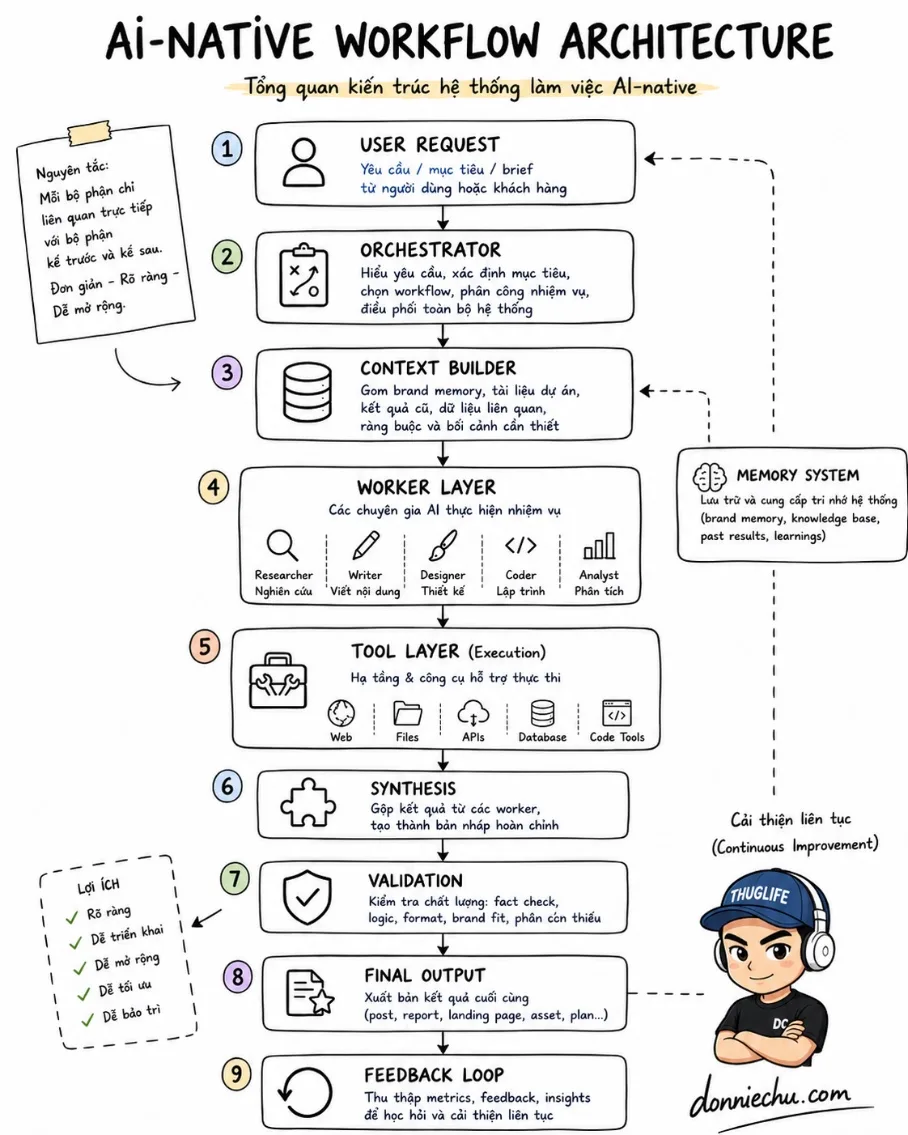
Nếu đang cân nhắc hướng đi, đây là roadmap thực tế. Bắt đầu từ RAG và evals - hai kỹ năng có feedback loop rõ nhất và dễ đo lường nhất. Context engineering sẽ đến tự nhiên khi bạn xây dựng hệ thống đủ phức tạp để nhận ra context window là tài nguyên có hạn cần quản lý chủ động.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ