
- Ngày 2/4/2026, Andrej Karpathy công bố "LLM Knowledge Bases" - pattern dùng AI xây dựng wiki markdown tự duy trì, đạt 16 triệu views và 5,000 GitHub stars chỉ trong vài ngày.
- Wiki của ông đạt ~100 bài viết, ~400,000 từ mà không cần tự viết một chữ.
- Pattern này cắt giảm token consumption lên đến 95% so với RAG thông thường và hoạt động hoàn toàn không cần vector database.
TL;DR
Andrej Karpathy - đồng sáng lập OpenAI, cựu AI lead của Tesla - vừa làm cộng đồng AI sôi sục với một post 16 triệu views: thay vì dùng LLM để viết code, ông dùng nó để xây dựng và duy trì personal knowledge base. Không phải RAG, không phải vector database, không phải NotebookLM. Chỉ là markdown files và một LLM đóng vai "compiler" bền bỉ. GitHub Gist mô tả pattern này vượt 5,000 stars trong vài ngày.
Tại sao mọi knowledge base đều chết yểu
Bạn đã từng xây dựng một Notion database 200 trang rồi bỏ xó sau 3 tháng chưa? Hay một Obsidian vault đầy hứa hẹn rồi để nguội dần? Lỗi không phải ở công cụ - lỗi ở chi phí bảo trì.
Thêm một bài báo mới nghĩa là: đọc, tóm tắt, tạo link đến các concept liên quan, cập nhật các trang đã có, kiểm tra contradiction với kiến thức cũ. Không ai làm điều này đều đặn. Wiki chết vì bookkeeping quá nặng.
Karpathy nhận ra: LLM làm chính xác cái việc nhàm chán đó - không mệt, không quên, không bỏ qua cross-reference. Chi phí bảo trì gần bằng 0.
Kiến trúc 3 lớp đơn giản đến bất ngờ
Toàn bộ hệ thống chỉ là một folder structure:
Layer 1 -
raw/: Tài liệu gốc bất biến - articles, papers, repos, datasets, images. LLM đọc nhưng không bao giờ sửa. Đây là nguồn sự thật duy nhất.Layer 2 -
wiki/: Markdown files do LLM tạo và duy trì - concept pages, entity pages, source summaries, comparison tables. Cóindex.md(catalog toàn bộ nội dung, LLM đọc trước khi trả lời) vàlog.md(nhật ký append-only mọi thao tác).Layer 3 -
CLAUDE.md: File cấu hình quan trọng nhất - định nghĩa conventions, templates, workflows. Biến LLM từ chatbot tổng quát thành wiki maintainer có kỷ luật.
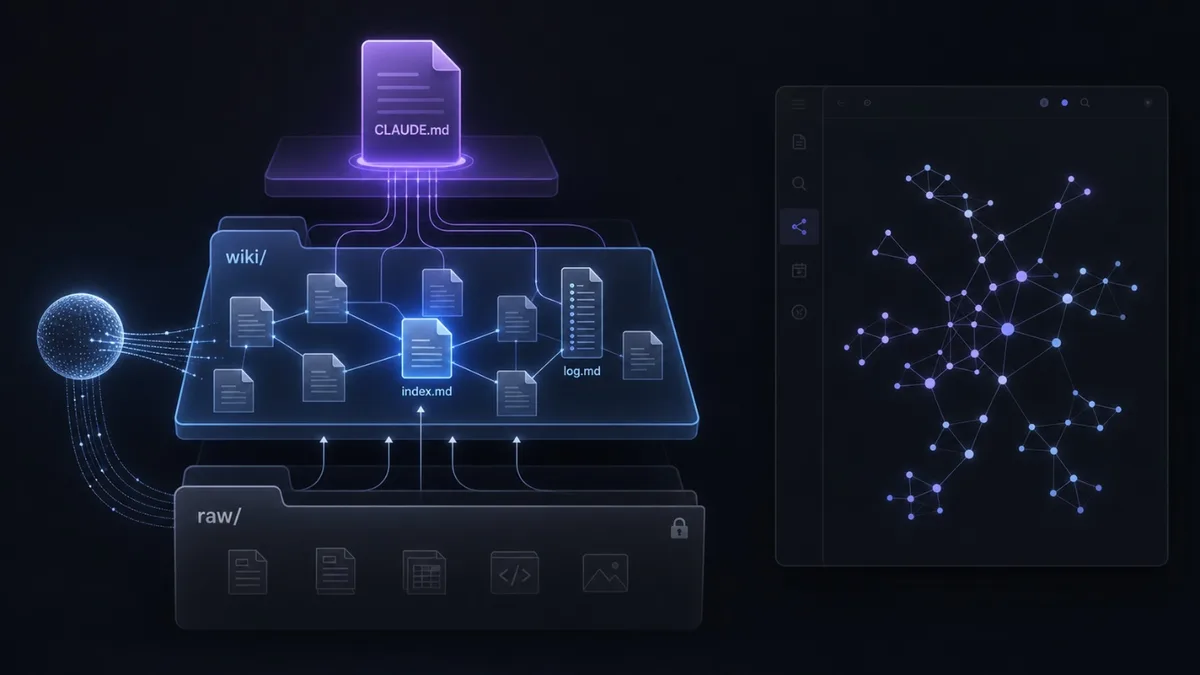
Obsidian là "IDE" để xem và điều hướng wiki. Graph view của Obsidian hiển thị toàn bộ mạng lưới wikilinks mà LLM tạo ra - giúp bạn thấy kiến trúc tri thức đang hình thành.
Ba thao tác vận hành wiki
Ingest: Bạn thả source mới vào raw/ và báo LLM xử lý. LLM đọc tài liệu, tạo summary page, cascade updates qua 10-15 wiki pages liên quan, tạo mới concept/entity pages nếu cần, cập nhật index.md, ghi log. Một source mới có thể chạm đến hàng chục trang wiki.
Query: Bạn hỏi câu hỏi phức tạp. LLM đọc index.md, tìm trang liên quan, tổng hợp trả lời có citation. Câu trả lời có giá trị - so sánh, phân tích, connection mới phát hiện - được file lại vào wiki như trang mới. Mỗi lần khám phá đều cộng dồn vào knowledge base.
Lint: Health check định kỳ. LLM quét tìm contradictions giữa các trang, orphan pages không có incoming link, claims bị supersede bởi nguồn mới hơn, gaps cần research thêm. Wiki ngày càng sạch và chính xác hơn.
Những con số đáng kinh ngạc
Metric | Con số |
|---|---|
Views bài post gốc (X/Twitter) | 16+ triệu |
GitHub Gist stars (vài ngày) | 5,000+ |
Wiki Karpathy (1 research topic) | ~100 bài, ~400,000 từ |
Giảm token so với naive loading | lên đến 95% |
Sweet spot (không cần RAG) | <50,000-100,000 tokens |
Pages cascade từ 1 source mới | 10-15 pages |
400,000 từ tương đương hầu hết luận án tiến sĩ - và Karpathy không tự viết một chữ nào.
LLM Wiki vs RAG vs NotebookLM
RAG (Retrieval-Augmented Generation) hoạt động thế này: mỗi lần query, hệ thống tìm kiếm chunks liên quan từ raw documents và đưa vào context. Vấn đề: không có sự tích lũy. LLM phải "khám phá lại" kiến thức từ đầu mỗi lần. NotebookLM và ChatGPT file uploads đều hoạt động theo cách tương tự.
LLM Wiki khác ở chỗ: kiến thức được compiled một lần, maintained liên tục. Cross-references đã có sẵn. Contradictions đã được flag. Synthesis đã phản ánh tất cả những gì bạn đọc. Khi bạn hỏi, LLM không cần reconstruct - nó chỉ cần navigate.
RAG vẫn thắng ở scale lớn (hàng triệu tokens), dữ liệu thay đổi liên tục (live pricing, news feeds), hoặc khi cần strict source attribution trong enterprise. Với personal knowledge base dưới 100-200 trang text đặc, LLM Wiki đơn giản hơn, đáng tin cậy hơn, và rẻ hơn đáng kể.
Ai nên dùng ngay hôm nay
Researchers & sinh viên PhD: Xử lý hàng chục papers, xây wiki research với backlinks tự động. Một giáo sư đại học đã dùng pattern này để compile toàn bộ research về entrepreneurship từ Google Drive.
Developers theo dõi tech landscape: Index articles, release notes, changelogs về một technology stack. Hỏi "so sánh approach X vs Y" - wiki đã có synthesis sẵn.
Knowledge workers: Competitive analysis, due diligence, course notes, hobby deep-dives - bất kỳ domain nào bạn cần accumulate knowledge theo thời gian.
Teams nhỏ: Internal wiki tự duy trì bằng cách feed Slack threads, meeting transcripts, customer calls. LLM làm cái việc bảo trì mà không ai trong team muốn làm.
Hạn chế cần biết trước khi dùng
Wiki là lossy compression: summarization có thể bỏ sót exact wording, caveats, minority views. Một LLM misread khi ingest có thể propagate lỗi sang các trang liên quan. Pattern này không có sẵn giải pháp cho multi-user concurrency, audit logs, hay compliance - không phải enterprise-grade out of the box.
Với multi-agent (Claude + Codex + Gemini cùng dùng 1 wiki theo thời gian), cộng đồng đã phát hiện 6 failure modes: CLAUDE.md drift, hidden parallel work tạo duplicate pages, open questions chết trong chat history. Project llm-wiki-coordination đang giải quyết các vấn đề này.
Cộng đồng & bước tiếp theo
Chỉ trong 1 tuần sau post của Karpathy, ecosystem bùng nổ:
SwarmVault v3.1: 48 agent integrations (Claude Code, Cursor, Windsurf...), durable memory ledger, local Whisper transcription offline
Keppi: Graph traversal layer - parse wikilinks thành weighted directed graph, tìm minimum context set cho mỗi query
Kompl: NLP trước LLM (spaCy NER + 4 keyphrase extraction methods) để reduce noise và cost
ΩmegaWiki: 23 Claude Code skills, 9 typed entities, 9 typed edges, bilingual EN/中文
Karpathy đề cập hướng tiếp theo đầy tham vọng: dùng wiki để generate synthetic training data và fine-tune model - để LLM "biết" domain knowledge trong chính weights của nó, không chỉ trong context window. Personal knowledge base trở thành personalized model.
Via: karpathy/llm-wiki.md, StarMorph Guide, MindStudio RAG Comparison.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ