
- Agent Swarm chạy subtask song song - thời gian tổng xấp xỉ max(A,B,C) thay vì A+B+C, giảm 3-4.5x wall-clock time.
- Kimi K2.6 là MoE 1 nghìn tỷ tham số, 32B active, 300 sub-agent đồng thời và 4.000 tool call mỗi session.
- Agent Swarm được train vào mô hình qua PARL - không phải framework gắn ở application layer.
- BrowseComp: swarm mode đạt 78.4%, tăng 17.8 điểm so với single-agent (60.6%).
TL;DR
Agent Swarm là kiến trúc multi-agent chạy các subtask độc lập song song, do một orchestrator điều phối - thay vì xếp hàng tuần tự. Khi task có cấu trúc song song thực sự, đó là sự khác biệt giữa vài phút và nhiều giờ đồng hồ. Kimi K2.6 là implementation open-source nghiêm túc nhất hiện tại: 1 nghìn tỷ tham số MoE, 300 sub-agent song song, 4.000 tool call mỗi session, và Agent Swarm được train vào mô hình - không phải gắn thêm ở application layer.
Bài này là phần 1 của series 3 bài. Phần 2 đi vào hạ tầng Mooncake và cách swarm hoạt động từng bước. Phần 3 cover 4 pattern kiến trúc, prompt design, và 7 guardrail không thể thiếu.
Agent Swarm là gì?
Task thực tế có chiều rộng. Năm mươi công ty cần nghiên cứu. Hai trăm file cần phân tích. Hàng chục subtask không phụ thuộc nhau và không cần xếp hàng chờ đợi. Agent Swarm là kiến trúc sinh ra cho những bài toán như vậy: nhiều agent làm việc đồng thời trên các subtask được phân rã, được điều phối bởi một orchestrator tổng hợp kết quả.
Điểm khác biệt so với sequential chain nằm ở cốt lõi:
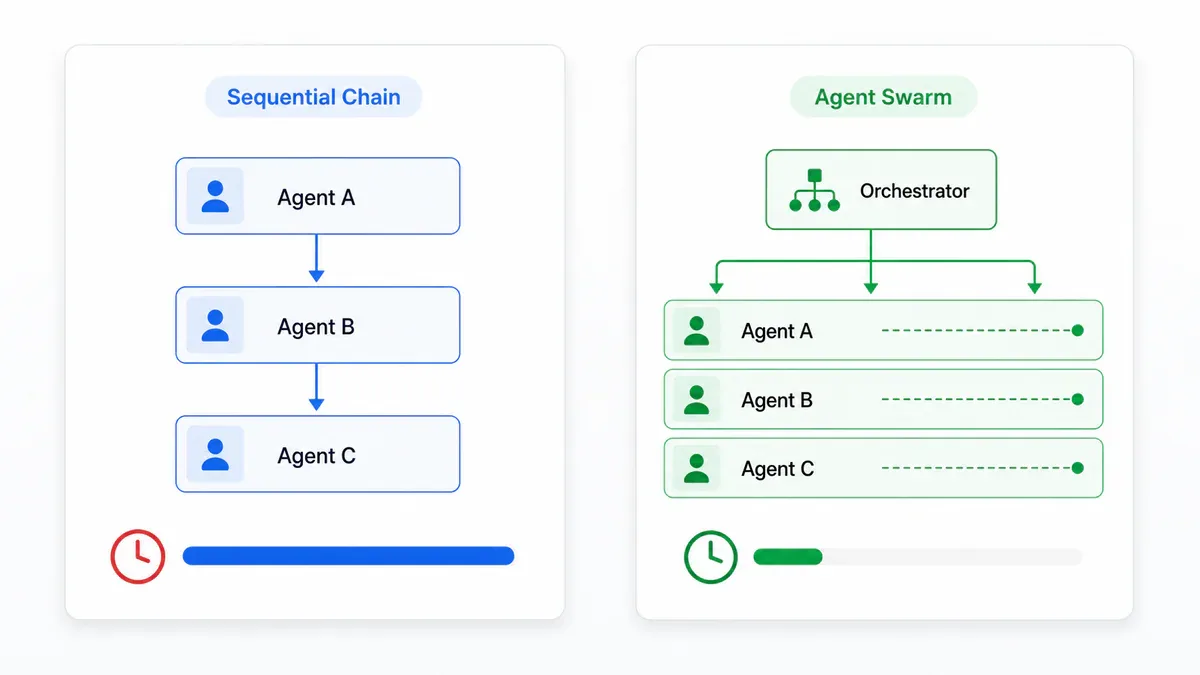
- Sequential chain: Agent A chạy, bàn giao cho B, B bàn giao cho C. Tổng thời gian = A + B + C.
- Swarm: Orchestrator chia nhỏ mục tiêu, các agent A, B, C chạy đồng thời trên subtask độc lập, kết quả được gộp lại. Tổng thời gian xấp xỉ max(A, B, C).
Swarm còn giải quyết bài toán context overflow. Một agent đơn lẻ trên task dài sẽ tích lũy token đến khi context window bị ngập. Swarm cho mỗi subtask context riêng biệt có giới hạn, và chỉ có structured output chảy ngược về orchestrator.
Sáu thành phần cốt lõi
| Thành phần | Vai trò |
|---|---|
| Orchestrator | Phân rã task, giao subtask, giám sát thực thi, tổng hợp kết quả |
| Subagents | Worker chuyên biệt cho từng domain (research, code, analysis, writing) |
| Tools | Hàm agent có thể gọi: web search, code interpreter, file I/O, API |
| Memory | Shared state swarm có thể đọc/ghi |
| Handoffs & Routing | Cơ chế chuyển control hoặc data giữa các agent |
| Guardrails | Giới hạn iteration, timeout, human-in-the-loop, error recovery |
Làm đúng cả sáu thứ này thì bạn có một swarm. Sai một thứ là bạn có một session debug đắt tiền.
Kimi K2.6 là gì?
K2.6 là mô hình Mixture-of-Experts (MoE) 1 nghìn tỷ tham số từ Moonshot AI, phát hành open-weight ngày 20/04/2026 dưới Modified MIT License. Sử dụng thương mại miễn phí dưới $20M doanh thu tháng hoặc 100M MAU - tức là miễn phí cho hầu hết các builder.
| Spec | Giá trị |
|---|---|
| Tổng tham số | ~1.04 nghìn tỷ |
| Kích hoạt mỗi token | ~32 tỷ (8 expert được chọn + 1 shared) |
| Tổng experts | 384, trải trên 61 transformer layers |
| Context window | 256K tokens (262,144 tokens) |
| Attention | Multi-Head Latent Attention (MLA) |
| Activation function | SwiGLU |
| Vision encoder | MoonViT-3D (400M params, image + video lên đến 2K) |
| Quantization | INT4 via QAT (~594GB trên disk) |
| Full weight FP16 | ~2TB trên 8x H100 80GB |
| License | Modified MIT |
Biến thể INT4 QAT chạy native trên 4x H100 80GB. Ba inference framework được hỗ trợ (vLLM, SGLang, KTransformers) đều expose OpenAI-compatible API.
MuonClip - Tại Sao Training Ổn Định
Train một sparse MoE nghìn tỷ tham số mà không bị "nổ" là bài toán khó. Failure mode cụ thể: khi sequence length tăng, tích vô hướng query-key (QK) trong attention layers có thể tăng không giới hạn. Kết quả là các đột biến loss, và ở scale này một đột biến loss có thể không hồi phục được.
Kimi K2 technical paper giới thiệu MuonClip để xử lý vấn đề này:
- Muon là gradient optimizer hiệu quả token hơn AdamW - cùng chất lượng, ít bước training hơn. Nhược điểm: Muon đơn thuần tạo ra attention instability ở scale nghìn tỷ tham số.
- QK-Clip thêm clipping per-token, per-head trực tiếp trên QK matrices trước softmax. Điều này giới hạn độ lớn attention score và triệt tiêu pathology explosion - không cần tuning thủ công, không cần hack learning rate.
"We present MuonClip, a novel optimizer that integrates the token-efficient Muon algorithm with a stability-enhancing mechanism called QK-Clip... Using MuonClip, Kimi K2 achieves competitive performance while requiring significantly fewer training tokens than AdamW baselines."
Tại sao builder cần quan tâm đến chi tiết training? Vì lý do K2.6 có thể sustain 4.000 tool call xuyên suốt 12+ giờ mà không bị degradation có nguồn gốc từ đây. Mô hình được train với attention instability có xu hướng hallucinate trong điều kiện long-context, high-step-count - đúng là regime mà Agent Swarm hoạt động trong đó.
PARL - Nghiên Cứu Đằng Sau Swarm
Agent Swarm không phải là framework được gắn lên K2.6. Hành vi này được train vào mô hình, thông qua paradigm Moonshot gọi là PARL: Parallel-Agent Reinforcement Learning, được mô tả trong Kimi K2.5 technical paper.
Orchestrator trainable, subagent frozen
Cách thông thường để xây multi-agent system là coordinate nhiều model instance live ở application layer. Nhưng credit assignment trở thành vấn đề: agent nào trong số các agent của bạn làm cho final answer tốt hay xấu? Train end-to-end qua graph đó là bài toán computationally intractable.
PARL né tránh điều này:
- Orchestrator là trainable, được cập nhật qua RL dựa trên outcome rewards.
- Subagents là frozen, các policy checkpoint cố định.
- Trajectories của subagent được xem như environmental observations, không phải differentiable decision points.
Credit chỉ đến với actions của orchestrator, không bao giờ đến 300 subagent đồng thời. Training ổn định vì chỉ một mô hình được update. Orchestrator học khi nào nên parallelize, bao nhiêu subagent cần spawn, và cách chia công việc - không ai chỉ định thủ công những hành vi này, chúng emerge từ reward maximization.
Hàm reward ba thành phần
Orchestrator được train theo ba tín hiệu:
r_PARL = λ1 · r_parallel (instantiation reward)
+ λ2 · r_finish (sub-agent finish rate)
+ r_perf (task-level outcome)- Parallelism reward - thúc đẩy spawn concurrent subagent thay vì chạy tuần tự. Không có reward này, mô hình mặc định về một agent một lần: an toàn, predictable, chậm.
- Finish reward - đảm bảo subagent thực sự hoàn thành task. Điều này chặn "spurious parallelism" - orchestrator spawn đám agent không làm gì chỉ để farm parallelism reward.
- Performance reward - đánh giá chất lượng output cuối cùng theo task objective. Đây là ground truth mà mọi thứ phục vụ.
Chi tiết thú vị nhất: metric tối ưu hóa là critical steps (độ dài critical path), không phải tổng số steps. Mô hình được thưởng khi rút ngắn dependency chain dài nhất, không phải khi maximize raw concurrency - đó mới là thứ thực sự giảm wall-clock time.
Kết quả đo được
- BrowseComp: Swarm mode đạt 78.4%, tăng 17.8 điểm tuyệt đối so với single-agent K2.5 (60.6%)
- WideSearch: Tăng 6.3 điểm tuyệt đối về Item-F1 (72.7% → 79.0%)
- Wall-clock time: Giảm 3-4.5x trên parallelizable tasks so với single-agent baseline
- K2.6 nâng tiếp: 300 sub-agent và 4.000 coordinated steps mỗi session
Kết Phần 1
Ba thứ cần nắm trước khi đọc tiếp: (1) Swarm là kiến trúc song song, không phải sequential chain nhiều bước. (2) K2.6 là MoE 1T params với Agent Swarm được train vào mô hình qua PARL - không phải application wrapper. (3) MuonClip giải quyết training instability ở scale nghìn tỷ - đây là lý do swarm có thể sustain hàng nghìn tool call mà không degradation.
Phần 2 đi vào hạ tầng Mooncake (tại sao 300 agent song song không sụp), cách swarm hoạt động từng bước, và tại sao Kimi + Claude Opus 4.8 là combo tối ưu.
via Kimi K2 technical paper & Kimi K2.5 technical paper (PARL)