
- GLM-5V-Turbo đạt 94.8 trên Design2Code, cao hơn Claude Opus 4.6 (77.3) và Kimi K2.5 (91.3).
- Mô hình 744B tham số (MoE) của Zhipu AI chạy 221.2 tokens/giây, rẻ hơn Claude ~4-6 lần với giá $1.20/$4.00 mỗi triệu token.
- Ưu thế tập trung vào visual-to-code: chuyển mockup, Figma, screenshot thành HTML/CSS chạy được ngay.
- Claude vẫn dẫn ở Flame-VLM-Code và text-only coding.
TL;DR
Ngày 3/4/2026, Zhipu AI (thương hiệu quốc tế: Z.ai) ra mắt GLM-5V-Turbo - mô hình multimodal vision coding đầu tiên được xây dựng native từ đầu, không phải ghép vision vào sau. Kết quả nổi bật nhất: 94.8 điểm trên Design2Code, cao hơn Claude Opus 4.6 (77.3) và Kimi K2.5 (91.3) theo số liệu Z.ai tự công bố. Giá chỉ $1.20/$4.00 mỗi triệu token - rẻ hơn Claude Opus 4.6 từ 4-6 lần.
Native multimodal - và tại sao điều đó quan trọng
Hầu hết các mô hình AI hiện tại được xây dựng theo kiểu "text-first, vision bolt-on" - tức là train xong mô hình ngôn ngữ rồi gắn thêm khả năng nhìn ảnh vào. GLM-5V-Turbo chọn hướng ngược lại: vision là một phần của kiến trúc ngay từ giai đoạn pretraining.
Điều này có nghĩa là mô hình không chỉ "thấy" ảnh - nó tích hợp thông tin hình ảnh vào quá trình lập luận, lên kế hoạch và sinh code theo cách tự nhiên hơn. Kết quả thực tế: bạn đưa một mockup Figma, screenshot giao diện cũ, hay thậm chí bản phác thảo tay - mô hình sinh ra HTML/CSS/JavaScript có thể chạy ngay lập tức.
Con số đáng chú ý
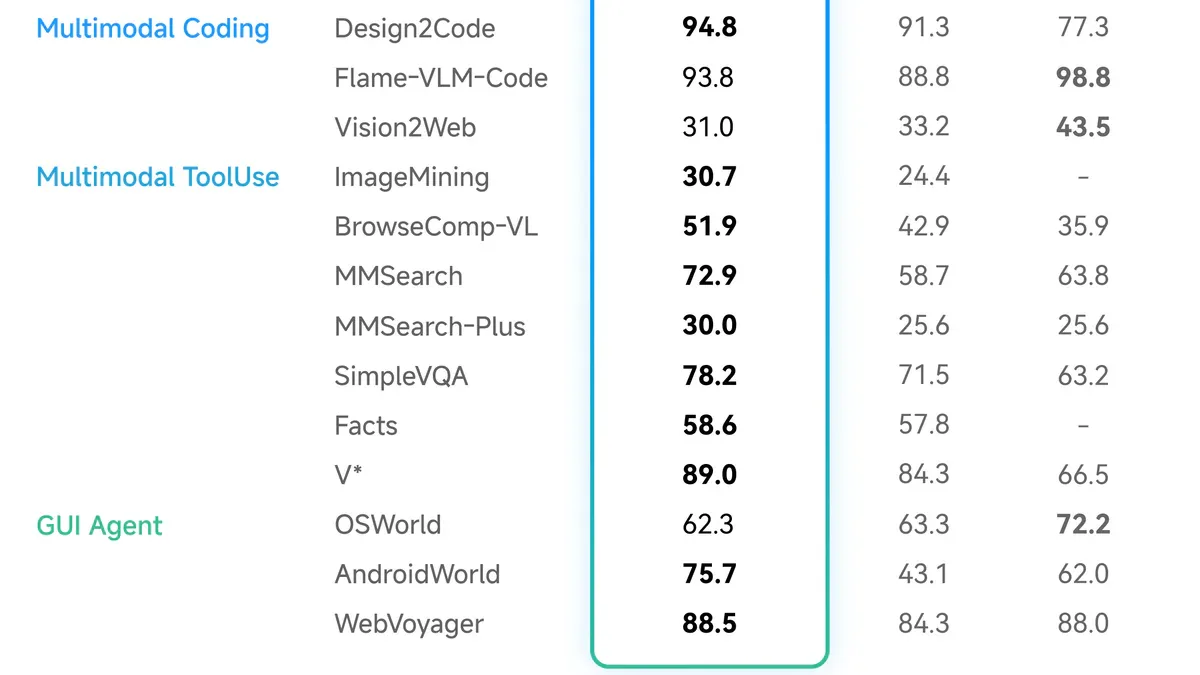
Dưới đây là toàn bộ bảng benchmark chính thức từ paper arxiv (2604.26752v2):
| Benchmark | GLM-5V-Turbo | Kimi K2.5 | Claude Opus 4.6 |
|---|---|---|---|
| Design2Code | 94.8 | 91.3 | 77.3 |
| Flame-VLM-Code | 93.8 | 88.8 | 98.8 |
| Vision2Web | 31.0 | 33.2 | 43.5 |
| WebVoyager (GUI) | 88.5 | 84.3 | 88.0 |
| AndroidWorld | 75.7 | 43.1 | 62.0 |
| BrowseComp-VL | 51.9 | 42.9 | 35.9 |
| MMSearch | 72.9 | 58.7 | 63.8 |
| OSWorld | 62.3 | 63.3 | 72.2 |
Nhìn vào bảng, bức tranh rõ hơn: GLM-5V-Turbo vượt trội ở Design2Code, AndroidWorld, BrowseComp-VL, và MMSearch - tất cả đều là task bắt đầu bằng visual input. Nhưng Claude Opus 4.6 vẫn dẫn ở Flame-VLM-Code, Vision2Web và OSWorld. Đây không phải "AI mới tốt hơn toàn diện" - mà là một công cụ chuyên biệt đã đạt đỉnh trong nhóm task của nó.
Ngoài ra, tốc độ inference đạt 221.2 tokens/giây (xếp hạng #5 BridgeBench SpeedBench), nhanh hơn cả Gemini 3.1 Pro và Claude Sonnet/Opus.
Kiến trúc đằng sau CogViT
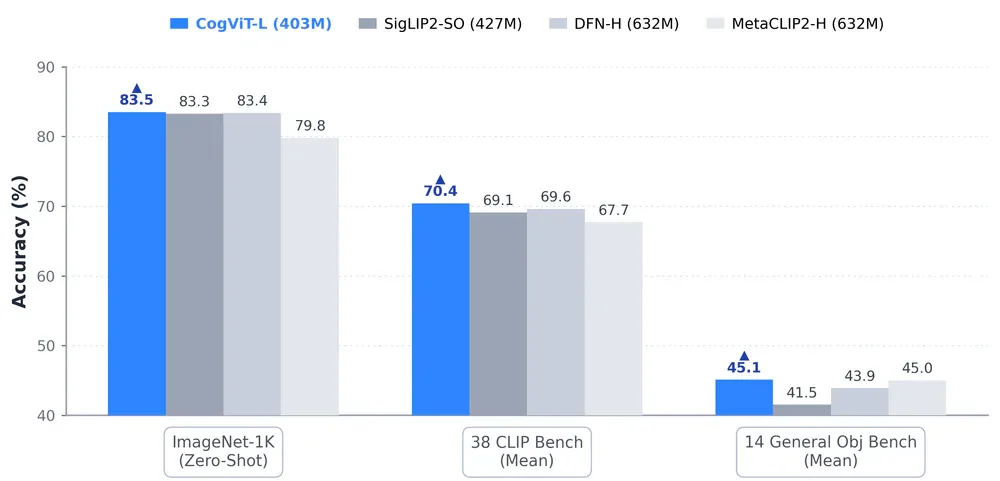
Vision encoder của GLM-5V-Turbo là CogViT-L (403M tham số) - nhỏ hơn nhưng hiệu quả hơn SigLIP2-SO (427M) và DFN-H (632M) trên cả 3 benchmark đánh giá (ImageNet-1K: 83.5 vs 83.3; 38 CLIP Bench: 70.4 vs 69.1; 14 General Obj Bench: 45.1 vs 41.5).
CogViT được train theo 2 giai đoạn:
- Giai đoạn 1: Distillation-based masked image modeling (masking ratio 35%), học từ 2 teacher đồng thời - SigLIP2 (semantic) và DINOv3 (texture). Data mix: 80% ảnh tự nhiên, 10% instruction-following, 10% ảnh khoa học.
- Giai đoạn 2: Contrastive image-text pretraining với NaFlex hỗ trợ variable-size input, corpus 8 tỷ cặp ảnh-văn bản song ngữ Anh-Trung.
Toàn bộ mô hình 744B tham số theo kiến trúc Mixture-of-Experts (~40B active per token), dùng INT8 quantization để tăng tốc inference. Context window 200K token input / 128K token output - đủ để xử lý toàn bộ codebase nhỏ hoặc video dài.
Trong thực tế - ai nên thử ngay
GLM-5V-Turbo không phải lựa chọn cho mọi task. Nhưng nếu workflow của bạn bắt đầu bằng một thứ nhìn thấy được và kết thúc bằng code, thì đây là mô hình đáng benchmark:
- Frontend developer: Upload Figma export hoặc screenshot thiết kế cũ, nhận React/Vue component hoặc HTML/CSS thuần. Early adopter báo cáo tiết kiệm 70-90% thời gian scaffolding.
- AI agent builder: GLM-5V-Turbo tích hợp với AutoClaw và OpenClaw framework, đạt AndroidWorld 75.7 - cao hơn Claude Opus 4.6 (62.0) và Kimi K2.5 (43.1) đáng kể.
- Document automation: PDF-to-Web, PDF-to-PPT, phân tích tài liệu phức tạp có bảng biểu, sơ đồ.
- Research pipeline: Thu thập thông tin từ web kèm visual evidence, tổng hợp báo cáo kết hợp text và hình ảnh.
Để so sánh giá: Claude Opus 4.6 hiện ở mức $5/M input - $25/M output. GLM-5V-Turbo: $1.20/$4.00 - tức là rẻ hơn 4x input và 6x output. Với workflow xử lý nhiều ảnh và sinh code dài, tiết kiệm chi phí là có thật.
Giới hạn cần biết
Một số điểm cần lưu ý trước khi chuyển toàn bộ workflow sang GLM-5V-Turbo:
- Số liệu tự công bố: Điểm 94.8 trên Design2Code là do Z.ai đo, chưa có lab độc lập xác nhận. Khoảng cách 17.5 điểm so với Claude đủ lớn để đáng xem xét, nhưng nên tự benchmark trên dataset nội bộ trước khi quyết định.
- Yếu ở text-only coding: CC-Backend chỉ đạt 22.8 - rất thấp. Nếu task chủ yếu là code logic backend không cần visual input, Claude vẫn là lựa chọn tốt hơn.
- Closed-source, API-only: Không có open weights, không thể self-host hay fine-tune.
- Agent training còn hạn chế: Vẫn phụ thuộc hand-crafted trajectories, chưa tự khám phá chiến lược mới.
- Video tiêu tốn context nhiều: Với input video dài, context budget cạn nhanh - cần tính toán kỹ trước khi dùng trong production pipeline.
Kết - công cụ chuyên biệt, không phải thay thế toàn diện
GLM-5V-Turbo không cố trở thành "AI giỏi nhất mọi thứ". Nhóm Zhipu AI chọn một phân khúc rõ ràng - visual-to-code - và tối ưu sâu cho đó. Kết quả là 94.8 trên Design2Code, nhưng đi kèm với điểm backend coding thấp và benchmark tự công bố chưa có xác nhận độc lập.
Roadmap tiếp theo theo paper: (1) agent training tự khám phá trajectory mới thay vì hand-crafted; (2) multimodal context compression hiệu quả hơn; (3) co-evolution giữa model và harness framework. Không có thông báo về open-source weights hay timeline cụ thể.
Nếu bạn đang làm frontend scaffolding, GUI automation, hay bất kỳ pipeline nào bắt đầu bằng ảnh - thử GLM-5V-Turbo là hợp lý. Nếu task chủ yếu là text và logic phức tạp, Claude Opus 4.6 vẫn là benchmark để so sánh.
Nguồn: arxiv 2604.26752 - GLM-5V-Turbo paper · The Decoder · Z.ai Official Docs