
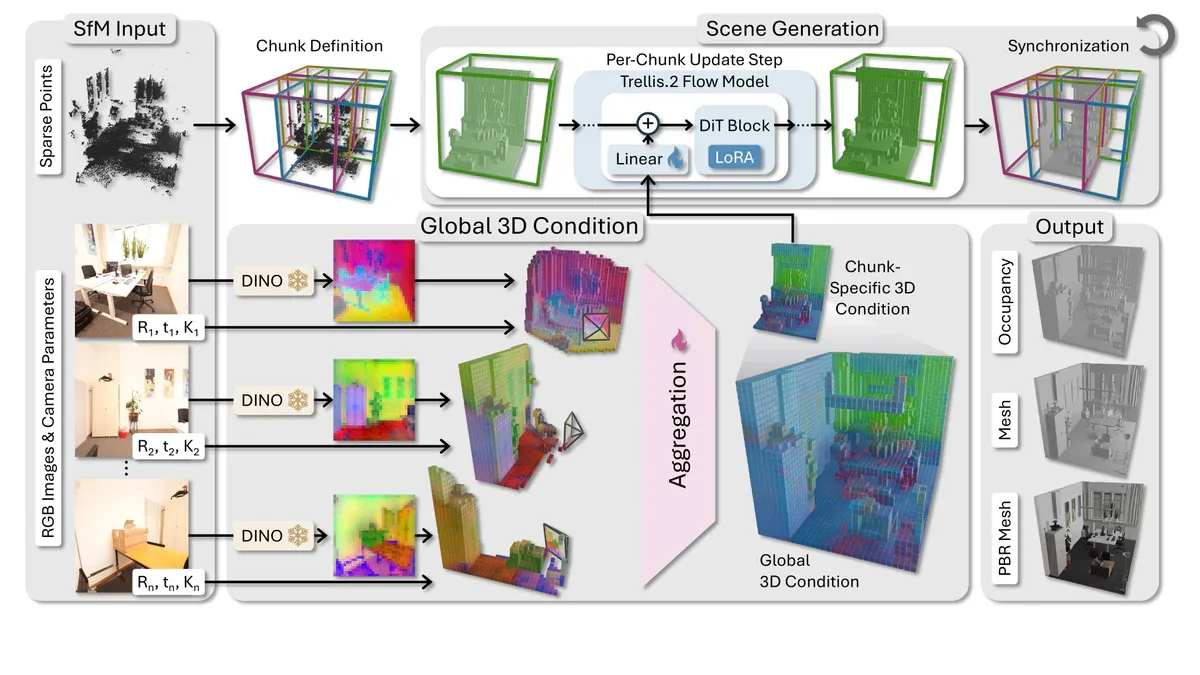
- GenRecon ghép Trellis.2 với projection-based 3D conditioning để dựng cảnh nội thất từ vài view RGB.
- Trên ScanNet++ thật, F-score@10cm đạt 0.777 và Chamfer 0.069m, vượt FineRecon và Murre.
- Trên 3D-FRONT, F-score gấp 1.4 lần baseline tốt nhất với chỉ 8 ảnh đầu vào.
- Output là PBR mesh edit được, nhập thẳng engine không cần per-scene optimization.
TL;DR
GenRecon là phương pháp tái dựng cảnh 3D từ vài ảnh RGB do Katharina Schmid, Nicolas von Lützow, Jozef Hladký, Angela Dai và Matthias Nießner (TUM + Huawei) công bố trên arXiv ngày 22/05/2026. Thay vì regression deterministic, nhóm casting bài toán thành conditional 3D generation trên các chunk voxel chồng lấn, nền là generative backbone Trellis.2. Trên ScanNet++ chỉ với 8 input view, F-score@10cm đạt 0.777, Chamfer 0.069m và normal consistency 0.786 - hơn FineRecon, Murre, DA3 ở gần như mọi metric. Output là mesh PBR (albedo + metallic + roughness) sẵn sàng cho relighting.

Vấn đề: feed-forward mạnh hình học, yếu fidelity
Các phương pháp feed-forward gần đây như DA3 hay FineRecon recover hình học bề mặt khá tốt từ ảnh đơn, nhưng output vẫn chưa đủ chuẩn cho content creation - thiếu chi tiết, hổng ở vùng chưa quan sát, không có material. Generative 3D prior thì mạnh ở fidelity và khả năng hallucinate hợp lý, nhưng đa số chỉ hoạt động ở mức object đơn lẻ, chưa scale ra scene. GenRecon nối hai dòng này lại: dùng generative prior để sinh, nhưng grounded chặt vào multi-view camera observations để không trôi khỏi cảnh thật.
Cách hoạt động: chunk overlap + projection conditioning
Pipeline có ba khối chính:
- Encoder ảnh: mỗi view RGB đi qua DINOv3 lấy feature 2D dày đặc.
- 3D lifting: feature từng view được lift vào lưới 3D canonical theo công thức projection
π_n(x) = K_n · T_n⁻¹(x + t_k). Aggregate kiểu IBRNet với MLP permutation-invariant tính mean và variance - kết quả không phụ thuộc thứ tự view. - Sinh joint cross-chunk: scene chia thành voxel chunk cố định kích thước
L³, kề nhau overlap tối thiểu m = 0.25. Joint generation theo MultiDiffusion: giữ một latent noisy grid phủ toàn scene, mỗi chunk dự đoán độc lập rồi trung bình hóa ở vùng overlap, đảm bảo biên không bị lệch.
3D condition tổng hợp được bơm residual vào 30 DiT block của Trellis.2 qua projection zero-initialized. Trellis.2 được fine-tune parameter-efficient bằng LoRA rank 8 trên attention layer, plus hai MLP 3 lớp cho aggregation - rẻ về compute, giữ được trọng số gốc.
Số liệu benchmark
Nhóm đánh giá trên 25 scene ScanNet++ thật và 25 scene 3D-FRONT synthetic, mỗi scene 8 input view, so với 2DGS, MonoSDF, DA3, FineRecon và Murre.
ScanNet++ (real-world):
| Metric | 2DGS | MonoSDF | DA3 | FineRecon | Murre | GenRecon |
|---|---|---|---|---|---|---|
| Depth MAE (m) | 0.260 | 0.250 | 0.124 | 0.094 | 0.107 | 0.102 |
| Depth LPIPS | 0.370 | 0.114 | 0.297 | 0.172 | 0.306 | 0.087 |
| Chamfer (m) | 0.218 | 0.125 | 0.100 | 0.082 | 0.098 | 0.069 |
| F-score@10cm | 0.487 | 0.632 | 0.691 | 0.769 | 0.726 | 0.777 |
| Normal consistency | 0.490 | 0.704 | 0.714 | 0.785 | 0.713 | 0.786 |
3D-FRONT (synthetic):
| Metric | 2DGS | MonoSDF | DA3 | FineRecon | Murre | GenRecon |
|---|---|---|---|---|---|---|
| Chamfer (m) | 0.592 | 0.339 | 0.209 | 0.223 | 0.158 | 0.064 |
| F-score@10cm | 0.177 | 0.346 | 0.550 | 0.513 | 0.601 | 0.866 |
Trên thật, GenRecon thua FineRecon ở Depth MAE đúng 8mm nhưng đổi lại perceptual depth (LPIPS), Chamfer, F-score và normal consistency đều dẫn đầu. Trên synthetic, F-score 0.866 gấp khoảng 1.4 lần Murre, cho thấy generative prior tận dụng được structure phân bố của dataset.

Ablation: 3D conditioning thật sự kéo điểm
Ablation trên SAGE-10k chunks cho thấy:
- Vanilla Trellis.2 (không fine-tune scene): Chamfer 0.345m, F-score 0.207, normal 0.234.
- Bỏ 3D condition, chỉ giữ DiT scene fine-tune: Chamfer 0.258m, F-score 0.367.
- Full method với 1 ảnh đầu vào: Chamfer 0.135m, F-score 0.631.
- Full method với 8 ảnh đầu vào: Chamfer 0.029m, F-score 0.968, normal 0.880.
Performance scale rõ ràng theo số view - càng nhiều ảnh, càng nhiều ràng buộc projection, càng ít chỗ cho prior hallucinate sai. Đây là điểm thực dụng cho ai capture cảnh bằng iPhone hoặc drone.
PBR mesh và relighting
Khác với baseline chỉ ra depth hoặc mesh trần, GenRecon trả về mesh kèm material PBR - albedo, metallic, roughness - nhập thẳng Blender, Unity hay Unreal được. Material phản ứng hợp lý dưới ánh sáng mới, dù chưa bằng phương pháp SVBRDF-estimation chuyên dụng về độ chính xác tuyệt đối. Với content creation và game prototyping, mức này đủ cho preview và iteration nhanh.

Ai nên thử
- Team AR/VR và game indoor: capture phòng bằng iPhone, ra mesh PBR sẵn dùng cho prototyping.
- Robotics và embodied AI: dựng cảnh kín nhất quán từ vài shot, hỗ trợ simulation và navigation - kể cả vùng chưa observe được hallucinate plausibly.
- Nghiên cứu generative 3D: cách scale object prior ra scene level qua chunk overlap và MultiDiffusion là pattern đáng đọc kỹ.
Hạn chế
- Non-Lambertian: glass, mirror, bề mặt phản xạ mạnh chưa được handle tốt do underrepresent trong training data.
- Chunk fixed: thiết kế hiện tại cho phòng vertical extent ~5m. Sảnh nhiều tầng hoặc cảnh outdoor cần adaptive chunking - chưa support.
- Hallucination: generative prior có thể bịa nội dung ở vùng weak evidence. Về metric net vẫn lợi, nhưng cần lưu ý khi dùng cho ứng dụng đòi hỏi ground-truth tuyệt đối.
- Code chưa release: repo
github.com/kasothaphie/GenReconghi Coming Soon, license CC BY-NC-SA 4.0 (non-commercial).
Kết
GenRecon là một trong những bài rõ ràng nhất 2026 về việc đưa generative 3D prior xuống cấp scene mà không hy sinh độ trung thực hình học. Projection-based conditioning + MultiDiffusion chunk fusion là cặp ý tưởng nên đọc cho ai làm reconstruction hoặc 3D content. Hy vọng code và pretrained weight sớm public - khi đó các team capture phòng bằng iPhone sẽ có thêm một lựa chọn pipeline thật sự khác biệt so với Gaussian Splatting truyền thống.
References
via project page, arXiv 2605.23888, arXiv HTML, demo video, Hugging Face.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ