
- Anthropic phân tích 400.000 phiên Claude Code từ 235.000 user trong 7 tháng.
- Người dùng nắm 70% quyết định planning, Claude nắm 80% quyết định execution.
- Expert đạt verified success 28-33%, gấp đôi novice (15%).
- Domain expertise quyết định kết quả, không phải coding skill.
TL;DR
Ngày 16/06/2026, Anthropic công bố báo cáo Economic Research phân tích privacy-preserving khoảng 400.000 phiên Claude Code từ ~235.000 người dùng giữa tháng 10/2025 và tháng 04/2026. Kết quả lớn nhất: người dùng quyết ~70% chuyện planning (làm gì, định nghĩa thế nào là xong), còn Claude quyết ~80% chuyện execution (sửa file nào, viết code ra sao). Phiên do user expert dẫn dắt đạt verified success 28-33%, trong khi novice chỉ 15%. Quan trọng hơn: thứ tạo ra khoảng cách đó là domain expertise, không phải khả năng code.

400.000 phiên, 7 tháng, một bộ dữ liệu kinh tế hiếm
Báo cáo lần này nối tiếp các nghiên cứu trước của Anthropic về autonomy của Claude Code. Khác biệt là họ không còn đo "Claude chạy bao lâu" hay "user approve tự động bao nhiêu phần trăm" - mà đo cụ thể: ai ra quyết định gì, mỗi prompt sinh ra bao nhiêu hành động tự chủ, và phiên đó có đi đến đích không.
Bộ dữ liệu trải dài 7 tháng (10/2025 → 04/2026), bao phủ Claude Code qua CLI, Claude.ai và desktop app. Phần headless mode (claude -p) và usage qua IDE third-party bị loại trừ vì đa số là programmatic. Phương pháp: dùng Claude Sonnet 4.6 làm classifier đọc transcript để phân loại task, infer occupation theo SOC taxonomy của Bureau of Labor Statistics, đánh giá expertise 5 mức, judge success. Mọi nhãn được cross-check với telemetry tự động - hơn 90% phiên được classify là "creating/modifying code" có code changes thực trong git activity.
Người và máy chia việc: 70/20 so với 30/80
Trong một phiên điển hình có khoảng 4 turn qua lại. Mỗi prompt user trigger trung bình ~10 hành động từ Claude, đôi khi vượt 100; Claude viết trung bình 2.400 từ output mỗi turn. Khi Anthropic bắt classifier liệt kê mọi "quyết định đáng kể" và quy về planning hay execution, kết quả gần như đối xứng:
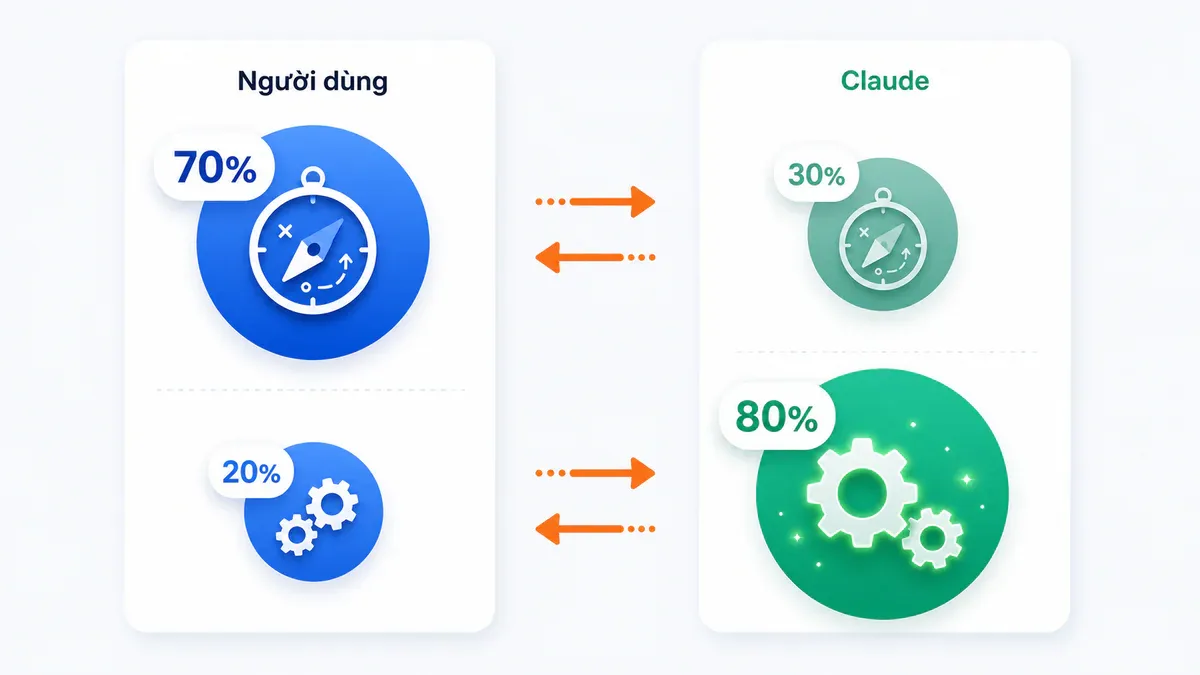
- Người dùng: ~70% quyết định planning, ~20% quyết định execution.
- Claude: ~30% planning, ~80% execution.
Sự phân công này không phải mới về ý tưởng, nhưng đây là lần đầu được đo trên quy mô lớn từ dữ liệu thật. Nó cũng giải thích vì sao prompting kém về context và yêu cầu sẽ kéo phiên đi sai - vì user vẫn là người set hướng, Claude chỉ nhận execution.
Khoảng cách thật giữa novice và expert
Anthropic định nghĩa verified success rất chặt: phiên vừa được judge là thành công, vừa có ít nhất một signal cứng (commit, test pass, user xác nhận rõ). Kết quả theo expertise:
- Novice: 15% verified success, partial success 77%.
- Intermediate → Expert: 28-33% verified, partial 91-92%.
- Khi phiên hit trouble (error, test fail, frustration): expert recover về verified success 15% trong khi novice chỉ 4%.
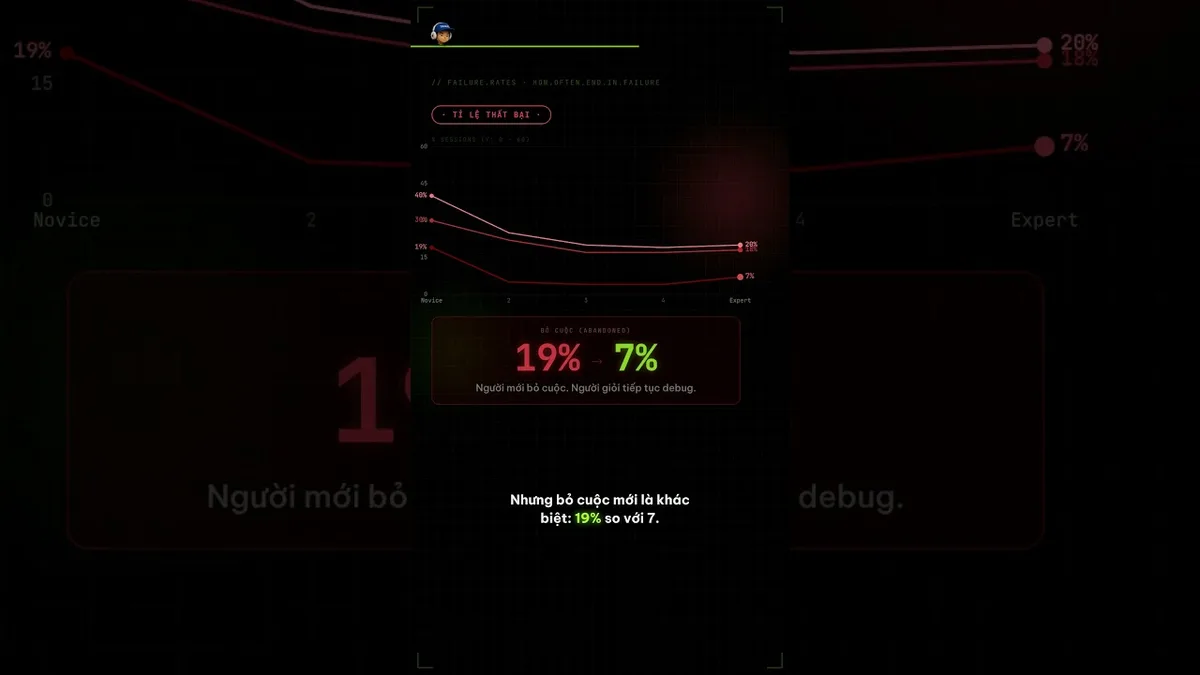
- Tỷ lệ bỏ cuộc (failed + 0 dòng code được viết): novice 19%, các nhóm khác chỉ 5-7%.
Một yếu tố thú vị nữa: output per prompt nhân theo expertise. Novice trung bình 5 actions và 600 từ output mỗi prompt; expert trung bình 12 actions và 3.200 từ. Cùng một câu hỏi, expert vắt ra gấp ~5 lần khối lượng công việc tự chủ của Claude.
Video ngắn dưới đây tóm lại đúng phần này - đặc biệt số liệu 19% so với 7% về tỷ lệ bỏ cuộc:
Cách công việc thay đổi sau 7 tháng
Một biểu đồ khác trong báo cáo bóc tách 9 work mode (writing, fixing, testing, orchestrating, operating, planning, understanding, analysis, prose). Tổng quan:
- 56% phiên xoay quanh code: writing 25%, fixing 26%, testing/orchestrating 5%.
- 17% operating software (deploy, monitor, run pipeline).
- 14% planning hoặc understanding system.
- 13% analysis hoặc prose - tức là dùng Claude Code cho việc không phải code.
Composition này dịch chuyển nhanh trong 7 tháng:
- Fixing code: 33% → 19% - giảm gần một nửa.
- Operating software: 14% → 21%.
- Writing và data analysis: ~10% → ~20% - gấp đôi.
Anthropic cũng ước tính giá trị kinh tế trung bình của mỗi phiên qua đối chiếu freelance marketplace: tăng 27% trong cùng 7 tháng. Building +43%, operating +34%, fixing +32%. Nói cách khác, Claude Code không chỉ làm nhiều hơn - mà còn được giao cho việc đáng tiền hơn.
"Expertise" thực sự nghĩa là gì?
Đây là phần đáng đọc kỹ nhất. Anthropic đo expertise task-specific, không phải job title. Classifier nhìn ba tín hiệu: (1) user frame yêu cầu chính xác đến đâu, (2) user yêu cầu Claude verify cái gì, (3) ai là người correct ai (user correct Claude hay Claude correct user).
Hệ quả: một senior engineer hỏi Rust lần đầu tiên trong đời = novice ở Rust. Một kế toán chưa bao giờ viết Python nhưng nói chính xác script reconciliation cần enforce rule nào và bắt được edge case ở month-end close = expert ở task đó. Ranh giới expertise dịch chuyển theo từng câu hỏi, không theo CV.
Số liệu occupation backup luận điểm này:
- Software-related: verified success 30% tổng thể, 34% trong phiên có code.
- Non-software: 26% tổng thể, 29% trong phiên có code.
- Khoảng cách chỉ 5 điểm và không nới rộng theo thời gian.
- Mọi top-10 occupation đều nằm trong 7 điểm so với software engineers.
- Management thậm chí cao hơn software engineers một chút - có thể vì kỹ năng delegation chuyển ngon sang việc điều khiển agent.
Ý nghĩa cho developer Việt Nam
Báo cáo này không phải sales pitch cho Claude Code. Nó là tín hiệu về labor market đang dịch chuyển. Một số take-away cụ thể:
- Đầu tư domain knowledge trở thành moat cá nhân. Trong thế giới nơi 80% execution có thể delegate được, hiểu nghiệp vụ - tài chính, y tế, pháp lý, logistics - quan trọng hơn việc nhớ thêm framework.
- Kỹ năng "prompt cho chuẩn" rẻ hơn nhiều so với kỹ năng "biết task này khó ở đâu". Người nói chính xác cái sai và edge case cần test sẽ đẩy Claude làm nhiều hơn 5 lần - cho cùng một prompt.
- Việc fixing đang teo lại. Tỷ trọng debug giảm gần một nửa trong 7 tháng. Thay vào đó là deploy, operate, analyze. Career trajectory "giỏi fix bug" có thể không còn là con đường dài.
- Non-coder không còn bị khoá ngoài cuộc. Marketer, lawyer, accountant với hiểu biết sâu lĩnh vực có thể tự build tool. Đây là cơ hội cho startup Việt nơi domain expert thường outnumber engineer.
Hạn chế của nghiên cứu
Anthropic tự nêu khá rõ:
- Họ không đo được outcome thực tế - code viết ra có dùng không, có tạo giá trị thật không, không ai biết.
- Headless mode và usage qua IDE third-party bị loại trừ - đây là phần lớn activity và có hành vi khác.
- Mọi classification dựa trên model đọc transcript. Họ thừa nhận khó validate at scale vì transcript quá dài để human label làm ground truth.
- Economic value tính qua match với freelance marketplace - chỉ nên đọc theo tương đối, không phải dollar tuyệt đối.
Một counter-confound đáng nhớ: expert hit trouble ít hơn, nên khi expert gặp trouble là kẹt ở bài thật sự khó (giá trị task khi trouble tăng gấp đôi từ novice → expert). Một phần recovery gap có thể do novice kẹt ở bài routine còn expert kẹt ở bài hard.
Kết
Nếu chỉ giữ một câu từ báo cáo này, đó là: coding agent không thay thế domain expertise - nó khuếch đại domain expertise đang có. Người có chuyên môn sâu, dù không từng code, vẫn đẩy được Claude làm việc đúng hướng. Người không có chuyên môn nào - kể cả khi biết code - sẽ chỉ thu được một phần nhỏ giá trị từ cùng một công cụ. Câu hỏi cá nhân không còn là "có nên học thêm framework không" mà là "mình nắm chắc nghiệp vụ nào đến mức có thể giao Claude làm toàn bộ phần implementation?"
References
via Anthropic - Agentic coding and persistent returns to expertise, CryptoBriefing, Claude Code product page, YouTube Shorts demo.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ