
- Wan-Streamer v0.1 chạy nghe, nhìn, suy luận, nói và sinh khung hình avatar trong cùng một mô hình.
- Model-side latency ~200 ms, tổng end-to-end ~550 ms khi cộng 350 ms network, output 25 fps.
- Bỏ hẳn pipeline cascaded VAD + ASR + LLM + TTS + avatar - tất cả thành một dòng token interleaved.
TL;DR
Wan Team thuộc Alibaba Group vừa công bố Wan-Streamer v0.1, một foundation model streaming end-to-end cho hội thoại full-duplex bằng video. Một Transformer duy nhất nghe audio, nhìn camera, suy luận, sinh giọng nói và dựng khung hình avatar - không còn cascaded ASR, LLM, TTS hay module animation rời rạc. Model-side latency ~200 ms, tổng end-to-end ~550 ms khi cộng 350 ms network, output 25 fps ở độ phân giải 192p (proof of concept).

Chuyện gì vừa xảy ra
Trong nhiều năm, mọi sản phẩm gọi là AI voice agent hay AI video avatar thực ra là một pipeline ghép từ nhiều mô hình rời: VAD phát hiện người nói, ASR chuyển giọng thành text, LLM suy luận, TTS đọc lại, rồi một mô hình audio-driven animation mới đẩy môi và biểu cảm sang avatar. Càng dài chuỗi, càng nhiều latency cộng dồn và càng dễ lệch tín hiệu giữa các module.
Wan-Streamer đi ngược triết lý đó. Toàn bộ chuỗi nghe - nhìn - nghĩ - nói - sinh khung hình được nhồi vào một Transformer duy nhất, với sequence được biểu diễn là token visual, audio và text xen kẽ ở cả input lẫn output. Block-causal attention giữ tính incremental để mô hình vừa nhận stream mới vừa phát stream ra, không cần đợi hết câu mới trả lời.
Kiến trúc: một dòng token cho mọi modality
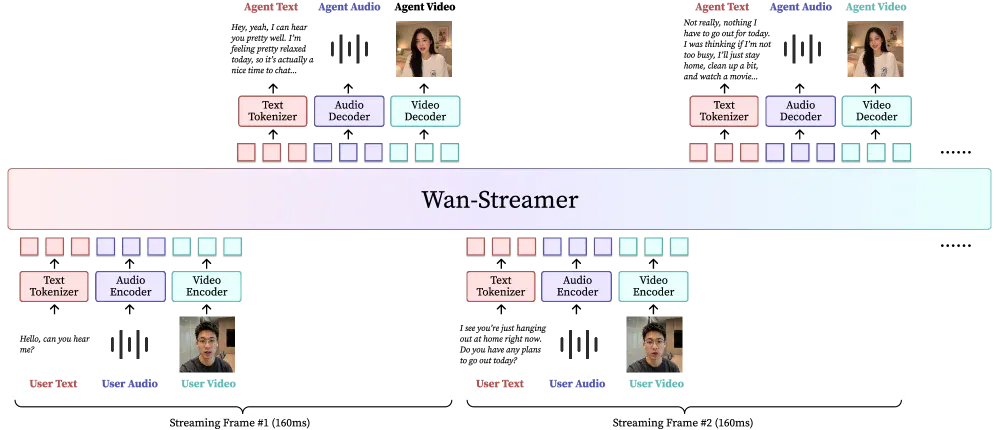
Hình trên là sơ đồ tổng quan trong paper. Ý chính:
- Có causal encoder cho từng modality (video, audio, text) đẩy về cùng không gian token.
- Có causal decoder ngược lại, sinh ra cả token text agent, token audio agent, lẫn token video avatar.
- Cả input và output được serialize thành một sequence theo thời gian, dùng block-causal attention để mỗi block mới chỉ thấy quá khứ - đúng yêu cầu của streaming.
- Token scheduler đa modality được thiết kế để giữ latency thấp khi nhiều stream chạy song song.
Hệ quả thiết kế là perception, reasoning, sinh giọng, sinh khung hình, quản lý lượt nói và đồng bộ chéo modality đều được học chung trong một mô hình thay vì lắp ghép từ các checkpoint rời.
Thinker - Performer: làm sao để chạy thực sự real-time
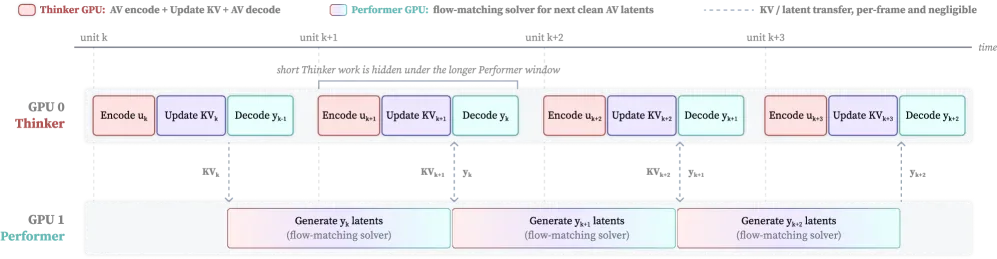
Để giảm latency, paper tách inference thành hai vai song song: thinker chịu trách nhiệm suy luận và lên kế hoạch nội dung, performer chuyên sinh ra audio + khung hình avatar. Hai vai chạy overlap giữa các đơn vị stream liên tiếp (mỗi unit 160 ms ở 25 fps), nghĩa là khi performer còn đang dựng khung hình cho unit hiện tại thì thinker đã bắt đầu lo unit kế tiếp.
Nhờ pipeline overlap này, Wan-Streamer đạt:
- ~200 ms latency phía mô hình (model-side response).
- ~550 ms tổng latency end-to-end, đã cộng giả định 350 ms cho network bidirectional.
- 25 fps video output liên tục, không phải burst rồi đứng.
Huấn luyện ba giai đoạn
Paper mô tả pipeline train chia làm ba bước:
- Independent-task pretraining: khởi tạo từ một language model, sau đó train multimodal encoder và decoder trên hỗn hợp task understanding và generation. Mục tiêu là kéo perception, ngôn ngữ và latent generation về cùng một sequence model.
- End-to-end interaction training: adapt mô hình với dữ liệu hội thoại duplex - text, audio, video của user và agent được xen kẽ trong cùng một causal stream. Mô hình học turn-taking và đồng bộ chéo modality từ chính dữ liệu này, không cần hard-code rule.
- Distillation cho low-latency: teacher model dùng classifier-free guidance được distill xuống một student gọn hơn. Họ áp dụng rolling distillation và self-forcing để chống suy giảm chất lượng trên hội thoại dài.
Vì sao kiến trúc này quan trọng
Khi mọi tín hiệu nằm chung một dòng token, mô hình có thể phản ứng với cả những thứ không xuất hiện trong lời nói. Paper nhấn mạnh agent có thể chủ động đưa ra bình luận hoặc câu hỏi dựa trên thứ nó nhìn thấy, thay vì đợi user phải nói một prompt cụ thể. Caption gốc trên Instagram mô tả demo có cảnh AI cười tự nhiên, gật đầu khi đang nghe và bắt chước biểu cảm khuôn mặt - đúng kiểu hành vi chỉ có khi visual + audio + reasoning cùng nằm trong một mô hình.
Full-duplex cũng kéo theo một định nghĩa khác về "đang nghe". Khi user nói, agent phải thể hiện hành vi nghe (gật, hướng mắt, micro-expression). Khi agent nói, nó vẫn phải perceive tín hiệu user để bị ngắt lời lúc nào thì biết dừng. Pipeline cascaded truyền thống rất khó làm điểm này vì mỗi module có vòng đệm riêng.
So sánh với cascaded và Qwen-Omni
Bảng latency trong paper đặt Wan-Streamer cạnh các bản Qwen3-Omni và Qwen3.5-Omni với first-packet latency dao động 234 - 651 ms. Nhưng họ kèm một ghi chú quan trọng: con số đó chưa bao gồm sinh khung hình avatar đồng bộ. Trong khi đó, ~550 ms tổng của Wan-Streamer đã là full path audio + video + thinking.
Nói cách khác, so sánh "đường về 200 ms" của một omni model rời với một mô hình end-to-end vừa nghĩ vừa dựng khuôn mặt nói là khập khiễng. Wan-Streamer đo cả mile cuối, gồm cả phần render avatar đồng bộ môi - thứ thường bị ẩn đi trong các benchmark voice-only.
Cùng nhóm Alibaba còn có LiveAvatar của team Quark - audio-driven avatar streaming với infinite length, đã có code mở trên GitHub. Hai project bổ sung nhau: LiveAvatar tập trung vào sinh avatar từ audio cho trước, Wan-Streamer thì gộp cả phần "nghĩ ra audio" vào.
Giới hạn thực tế
Đây vẫn là research release v0.1. Một vài giới hạn cần để ý nếu bạn định mơ về use case ngay:
- Output mới chỉ ở 192p. Paper nói scale lên cao hơn là straightforward nhưng để future work.
- Chưa có public API hay pricing. Đây là bản công bố nghiên cứu, không phải sản phẩm sẵn dùng.
- Con số 550 ms phụ thuộc giả định 350 ms network. Network thật tệ hơn thì trải nghiệm tệ hơn.
- Paper không công bố failure mode chi tiết - không rõ mô hình ứng xử ra sao khi camera tối, có nhiều khuôn mặt, hoặc khi user nói chen.
Ai nên để ý
- Team xây digital human / virtual presenter: đây là blueprint kiến trúc cho thứ vốn phải ghép từ năm mô hình.
- Team voice agent thật-time: phần latency overlap và full-duplex là bài đáng đọc kỹ.
- Researcher multimodal: ý tưởng đẩy mọi modality vào cùng một stream causal có khả năng được generalize sang nhiều task khác.
- Người làm sản phẩm support / education / streamer: chưa dùng được ngay nhưng giúp hình dung một thế hệ avatar đối thoại tiếp theo.
Kết
Wan-Streamer là một thử nghiệm về cái xảy ra khi bạn ngừng coi voice agent là "LLM cộng plugin" và bắt đầu coi nó là một mô hình duy nhất xử lý mọi tín hiệu thời gian thực. Bản v0.1 còn 192p, còn là research, nhưng đường ray đã được đặt: nghe, nhìn, nghĩ, nói, dựng khuôn mặt - cùng một sequence, cùng một loss, cùng một attention.
Đạo hữu là phàm nhân, tu tiên giả
... hay AI cào nội dung?
Tất cả nội dung tại đạo quán đều miễn phí. Đạo hữu chỉ cần nhập email của mình để đọc tiếp. Nói KHÔNG với Spam. Huỷ subcribe lúc nào đạo hữu thích.
nếu không muốn nhận newsletter thì có thể nhập mail phụ